简介
- 对象的创建和销毁需要一定的开销,线程亦是对象,创建线程和销毁线程必然也需要同样的开销。
- 在某些情况下,线程执行的任务耗时不长,但是任务很多。这样就导致频繁的创建、销毁线程,需要很大的时间开销和资源开销。线程池应运而生。
- 线程池相当于在这一个池中维护多个线程,需要执行任务时从池中取出一个线程用来执行任务,任务执行完成后将线程放回池中。这样也就减少了开销。
- 因为减少了每个任务调度的开销,所以它能在执行大量异步任务的场景中提供更好的性能。并且它提供了一种限定和管理资源(比如线程)的方式。他也会保存一些基本的统计信息,比如已完成的任务数量。
Executor
Executor 接口中只有一个方法:
1 | void execute(Runnable command); |
command 为待执行的任务。
ExecutorService
ExecutorService 接口继承自 Executor 接口,并扩展了几个方法:
关于状态:
1 | // 发出关闭信号,不会等到现有任务执行完成再返回,但是现有任务还是会继续执行, |
执行单个任务(立刻返回一个Future存储任务执行的实时状态):
1 | <T> Future<T> submit(Callable<T> task); |
执行多个任务(前两个方法等到所有任务完成才返回,后两个方法等到有一个任务完成,取消其他未完成的任务,返回执行完成的任务的执行结果):
1 | <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) |
AbstractExecutorService
该抽象类实现了 ExecutorService 接口,并提供了 ExecutorService 中各方法中的具体实现。例如 submit() 方法:
1 | public Future<?> submit(Runnable task) { |
并扩展了两个 newTaskFor() 方法:
1 | protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) { |
FutureTask 是任务和执行结果的封装类。它实现了 RunnableFuture 接口,RunnableFuture 接口继承了 Runnable 和 Future 接口。可以通过 get() 方法获取任务的执行结果。
ThreadPoolExecutor
ThreadPoolExecutor 继承自 AbstractExecutorService。
初始化参数介绍
1 | public ThreadPoolExecutor(int corePoolSize, |
- corePoolSize: 核心线程数。新任务提交过来时,如果当前活动的线程数少于 corePoolSize 会创建一个新线程来处理这个新任务即使当前有空闲线程。
- maximumPoolSize:最大线程数。如果当前线程数大于 corePoolSize 小于 maximumPoolSize 且任务队列已满时也会创建新线程。
- keepAliveTime:如果当前线程数量超出了 corePoolSize,超出的那部分非核心线程会在空闲超出 keepAliveTime 时被终止。这能够在线程池活跃状态不足时及时回收占用的资源。默认情况下核心线程超时不回收,可以通过配置 keepAliveTime 和 allowCoreThreadTimeOut 来允许核心线程超时回收。
- unit:超时时间单位
- workQueue:任务等待队列,存放任务
- threadFactory:线程工厂用于生产线程。可以自定义实现
- handler:也就是参数 maximumPoolSize 达到后丢弃处理的方法,java 提供了4种丢弃处理的方法;java 默认的是使用 AbortPolicy ,他的作用是当出现这中情况的时候会抛出一个异常。
- AbortPolicy: 拒绝提交,直接抛出异常,也是默认的饱和策略;
- CallerRunsPolicy: 线程池还未关闭时,用调用者的线程执行任务;
- DiscardPolicy: 直接丢弃任务
- DiscardOldestPolicy:线程池还未关闭时,丢掉阻塞队列最久为处理的任务,并且执行当前任务。
Executors 构造 ThreadPoolExecutor 对象
Executors 类提供了几个构造 ThreadPoolExecutor 对象的静态方法:
newCachedThreadPool()
1
2
3
4
5
6
7
8
9
10
11
12public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}线程数量没有上界(Integer.MAX_VALUE),有新任务提交并且没有空闲线程时,创建一个新线程执行该任务,每个线程空闲时间为 60s, 60s 空闲后线程会被移出缓存。使用
SynchronousQueue作为任务队列的实现类。适用于执行大量生命周期短的异步任务。
newFixedThreadPool()
1
2
3
4
5
6
7
8
9
10
11
12public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}固定容量的线程池。使用
LinkedBlockingQueue作为任务队列的实现类。当新任务到达时,创建新线程,当线程数达到上限时,将任务放到队列中,任务队列中任务数量没有上界。当线程创建之后就一直存在直至显式的调用shutdown()方法。
newSingleThreadExecutor()
1
2
3
4
5
6
7
8
9
10
11
12
13
14public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}单个 Worker 的线程池。和
newFixedThreadPool(1)类似,区别在于这个实例经过了一次封装,不能对该实例的参数进行重配置,并且实现了finalize()方法,能够在 GC 时调用shutdown()方法关闭该线程池。
newScheduledThreadPool()
1
2
3
4
5
6
7
8public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}ScheduledThreadPoolExecutor 的功能主要有两点:在固定的时间点执行(也可以认为是延迟执行),重复执行。
newSingleThreadScheduledExecutor()
1
2
3
4
5
6
7
8
9public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}将 ScheduledThreadPoolExecutor 进行一层包装。
状态转换
ThreadPoolExecutor 中一些状态相关的变量和方法如下:
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
线程池的状态在 ThreadPoolExecutor 中通过 AtomicInteger 类型的成员变量 ctl 的高3位表示。
- RUNNING: 111
- SHUTDOWN: 000
- STOP: 001
- TIDYING: 010
- TERMINATED: 011
变量 ctl 的低29位表示的有效工作线程数。
各状态之间的转换如下图:
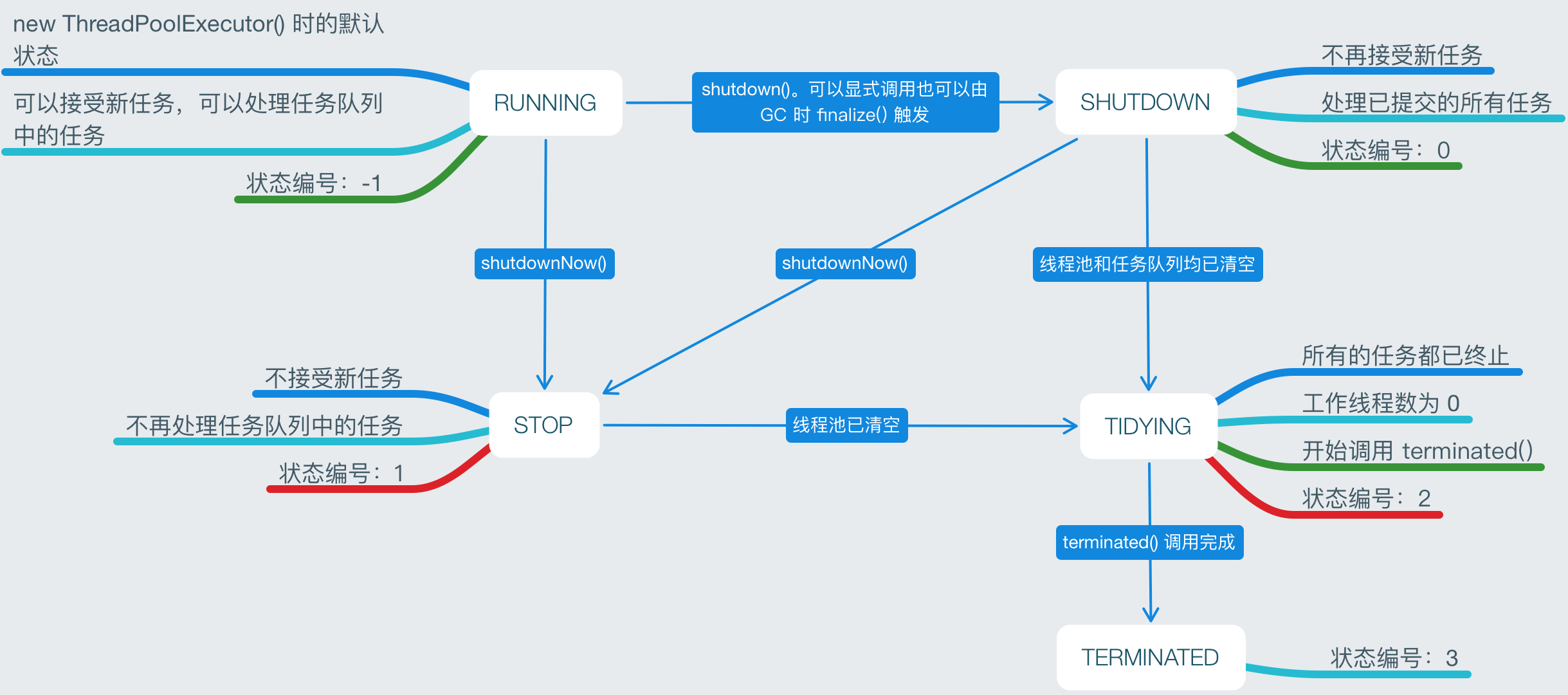
- SHUTDOWN 想转化为 TIDYING,需要 workQueue 为空,同时 workerCount 为0。
- STOP 转化为 TIDYING,需要 workerCount 为0
方法解析
execute()
1 | public void execute(Runnable command) { |
addWorker()
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
runWorker()
ThreadPoolExecutor 有一个成员类叫 Worker
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable |
这里 AbstractQueuedSynchronizer 的作用是使Worker具有锁的功能,在执行任务时,会把 Worker 锁住,这个时候就无法中断 Worker。Worker 空闲时候是线程池可以通过获取锁,改变 Worker 的某些状态,在此期间因为锁被占用,Worker 就是不会执行任务的。
Worker工作的逻辑在ThreadPoolExecutor#runWorker方法中
1 | final void runWorker(Worker w) { |
shutdown()
1 | public void shutdown() { |
接着看下 interruptIdleWorkers() 方法:
1 | private void interruptIdleWorkers() { |
shutdownNow()
1 | public List<Runnable> shutdownNow() { |
总结
本文从 ThreadPoolExecutor 的类继承体系,到初始化参数详解,再到状态转换以及重要方法的解读,由浅入深的介绍了 ThreadPoolExecutor。通过本文可以对线程池的运行原理有一个最基本的理解。